
Misunderstood Business Continuity risk domain
A look at Business Continuity Management (BCM); The process that is responsible for Disaster Recovery Plan (DRP) and Business Continuity Plan (BCP) using Business Impact Analysis (BIA) enabling Operational Resilience through HA and DR principles

Business Continuity Management (BCM); The process that is responsible for Disaster Recovery Plan (DRP) and Business Continuity Plan (BCP).
My personal favorite security and risk domain area, one that has broad reaching and often misunderstood scope but can be the most valuable aspect of any information security management system (ISMS).
Commonly constrained to just Operational Resilience, which is likely because a lot of us think technically. BCP is as much about contractural arrangements, process, policy and ritual than perhaps just the technical implementations we all focus on when the topic comes up.
Over-arching process
One of the most famous examples of BCP comes from the NIST SP800-34 which has focus on process and policy but the guidance lacks in clear actionable steps.
In fact if you look at everyones favorite inspiration; the CSA Security, Trust & Assurance Registry (STAR) framework. you'll find one of the 16 domains is Business Continuity Management & Operational Resilience bundled together in such a way that comes across in terms most of us should understand.
So what goals are we discussing?
- Determine criticality
- Estimate max downtime
- Evaluate internal and external resource requirements
Lets break these down into a process, to answer each we will need to;
- Gather information
- Analyse information
- Perform threat analysis
- Document results and present recommendations
Once you have developed the continuity planning policy, identified preventive controls, have a recovery strategy and contingency plan - you'll need to test the plan and conduct training and exercises to ensure you can maintain the plan.
Business Impact Analysis (BIA)
One of the most important first steps in the planning development. Qualitative and quantitative data on the business impact of a disaster need to be gathered, analyzed, interpreted, and presented to management.
One of the tools to determine criticality and effectively report on threats is called a Business Impact Analysis. A BIA involves the selection of individuals to interview for data gathering through surveys or questionnaires (remember to gather evidence to support your conclusions).
Use the learnings of this exercise to identify the company's critical business functions and the resources these functions depend on, and ensure you gather the data needed so you can calculate how long these functions can survive without these resources.
It is important to also perform threat and risk analysis (TRA) for each of these functions, however I will deep dive on this subject in a future post.
Formula: Risk = Threat * Impact * Probability
Disaster Recovery Plan (DRP)
Carried out when everything is going to still be suffering from the effects of the disaster.
Management should be involved in setting the overall goals in continuity planning so before going ahead with any work ensure you have senior management support.
The goal of disaster recovery is to minimize the effects of a disaster whereas the goal of business continuity is to resume normal business operations as quickly as possible with the least amount of resources necessary to do so.
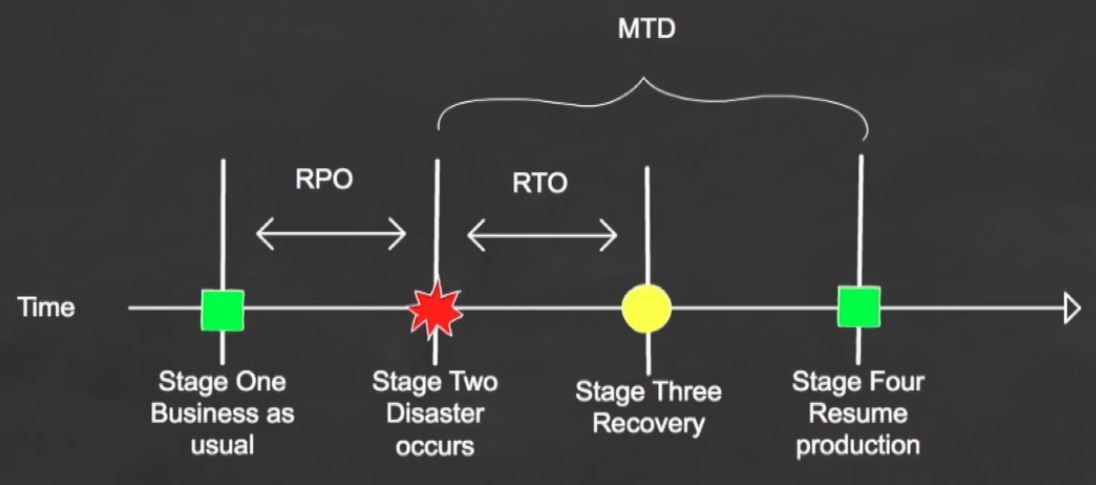
Your acceptable amount of data loss measured in time is called a Recovery Point Objective (RPO).
The earliest time period and a service level within which a business process must be restored after a disaster. Your Recovery Time Objective (RTO) value is smaller than the Maximum Tolerable Down-time (MTD) because the MTD represents the time after which an inability to recover will mean severe damage to the business's reputation and/or the bottom line.
The RTO assumes there is a period of acceptable down-time. Setting a Work Recovery Time (WRT) allows for the remainder of the overall MTD value.
MTD, RTO and RPO values are derived during the BIA
Business Continuity Plan (BCP)
Used to return the business to normal operations.
BCP contains strategy documents that provide detailed procedures that ensure critical business functions are maintained. A BCP provides procedures for emergency responses, extended backup operations, and post-disaster recovery.
Types of organisational changes that should be identified and included in the manual include staffing and key clients/vendors/suppliers as well as some specialised technical resources that include anti-virus (AV), patching, hardware, and data applications.
Testing and verification of recovery procedures are important because as work processes change, previous recovery procedures may no longer be suitable. Ensure all work processes for critical functions are documented before changes reach production so if the systems used for critical functions changed there are documented work checklists that are meaningful and accurate so the business is capable of performing recovery tasks and supporting disaster recovery infrastructure within the predetermined recovery time objective.
Mean Time To Failures (MTTF) and Mean Time To Repair (MTTR) are two important KPI's, senior management will ask for both but at a technical level you only need to measure MTTF while putting focus on reducing MTTR.
Embrace failure
When you start ignoring MTTF by only measuring it you might be blamed for allowing constant failures to continue, but by reducing the MTTR close to zero you're proving that any single failure or no failure is as impactful as double the most failures you ever experienced.
Mean Time To Failures = (Total up time) / (number of breakdowns)
Mean Time To Repair = (Total down time) / (number of breakdowns)
MTTF is literally the average time elapsed from one failure to the next. Usually people think of it as the average time that something works until it fails and needs to be repaired.
How to achieve resiliency
I talked about embracing failure and allowing them to occur while focusing on that MTTR, this is what is referred to as being resilient.
Resiliency is the ability of a system to recover from failures and continue to function. It's not about avoiding failures, but responding to failures in a way that avoids downtime or data loss.
Two important aspects of resiliency are High Availability (HA) and Disaster Recovery (DR) where HA is the ability of the application to continue running in a healthy state and DR is the ability to recover from non-transient or wide-scale failures.
By HA we must retain "healthy state" which simply put means the application is responsive, and users can connect to the application and interact with it. To achieve this you must load balance users across multiple geographic areas, preferably three regions is HA because having only two is better defined as being a fail-over or blue-green strategy rather than HA.
Data backup is a critical part of DR because if data is lost the system can't return to a stable state. Data must be backed up in a different geographical region to enable HA. Backup is distinct from data replication however for the purposes of HA you may design for either or both however replication won't protect against human error. If data gets corrupted because of human error, the corrupted data just gets copied to the replicas and to have DR you must rely on backups still.
Conclusion
Everyone likes numbers and percentages so like this post, the organisation should have a 80/20 percent split of 80% process 20% technical for Business Continuity management but that is only an upfront investment to what will be 100% embracing the chaos.
Ritual; or rather practice; will play key roles in your ability to execute during live incidents. The goal of the whole organisation (not just the technical people) should be the ability to automatically recover from all failures, failures should be permitted but only occur in a way that is of no consequence to the business.
However to get any of this done in reality you should execute proper planning and document everything. Policy reinforces practice, analysis appeases auditors, and process enables humans. Investing in planning is profit for enterprise.
Some people must persevere the process so that others may fully embrace the chaos.
Honorary DevOps shout-out
Skip if you came for the serious content.
Some of you may find the end goal to be familiar if you've been exposed to DevOps.
Contrary to popular modern hype of DevOps, the roots of what DevOps is and to most of us from that time it always has been, is the ability and freedom to move fast, experiment, and learn from breaking things.
We could have only ever achieved such luxury in enterprise if we are capable of doing so within the legal and contractural constraints of the business - which is to say we ensure critical systems do not suffer our foolery.
Today; DevOps is a bit of a joke. Rather, it is misunderstood and often due to the recruitment process it has been transformed into some glorified playground for millennials to take contract after contract building bespoke glittery unicorn systems without any regard for what the business needs.